

W Lśnieniu Stanleya Kubricka Jack Torrance (Jack Nicholson) wyłamuje siekierą dziurę w drzwiach i wkłada głowę w poszukiwaniu swojej żony – Wendy. Podobnie w dzisiejszych czasach ze wszystkich stronach “puka” do nas termin Uczenie Maszynowe (ang. Machine Learning).
Co więcej, często termin ten jest mieszany lub używany zamiennie z wyrażeniami Sztuczna Inteligencja (Artificial Intelligence, AI), Data Science czy Głębokie Uczenie Maszynowe (Deep Learning). Część osób czuje zmieszanie, część zagubienie, a część nawet strach – bo co jak te maszyny się nauczą i nas zniszczą?

Moja reakcja na początku była podobna, jak żony Jacka – nóż w dłoń, defensywa i krzyczymy! Na szczęście zebrałem siły, stawiłem czoła “włamywaczowi” i okiełznałem wszechobecną terminologię. Pozwól, że i Tobie pomogę zrozumieć i wyjaśnię, co to jest machine learning.
Czym właściwie jest Uczenie Maszynowe?
Czy pobranie dużej ilości danych do pamięci komputera to uczenie maszynowe? Czy jeśli zainstaluję na dysku twardym encyklopedię, to moja maszyna jest „nauczona”? Nie do końca…
“Synek, a czym ty się tak w ogóle zajmujesz?” – wyjaśnienie Uczenia Maszynowego dla osób nietechnicznych
Kwietniowy, ciepły dzień. Byłem pomiędzy zupą a schabowym podczas sobotniego obiadu u rodziców. Gdy nakładałem ziemniaki, usłyszałem pytanie z nagłówka:
– A co ty tak w zasadzie robisz synek? Czym ty się zajmujesz?
W mojej głowie automatycznie pojawiła się definicja machine learningu. Do tego stanowisko – inżynier uczenia maszynowego. Że są modele, datasety, klasyfikacje, detekcje, dystrybucje i regresje. Powstrzymałem jednak gonitwę myśli i ze spokojem wyjaśniłem:
– Mamo, pamiętasz, jak kiedyś mówiłem, że jestem programistą? Że piszę pewne reguły, a później komputer przyjmuje jakieś informacje np. od użytkownika takiego jak ty, przetwarza je według tych moich reguł, a na koniec zwraca rezultat?
– No pamiętam, pamiętam. Ale jedz bo stygnie.
– Właśnie, to teraz mamy “software 2.0”, lepsze programy – zamiast pisać te reguły ręcznie, zbieram dużo informacji, które normalnie trafiłyby do mojego programu i trenuję program, żeby sam sobie te reguły znalazł. I to podejście nazywa się Uczenie Maszynowe, a z angielskiego Machine Learning.
Daję maszynie bardzo dużo informacji, a maszyna uczy się na podstawie tych informacji i swoich błędów. Dzięki temu mogę rozwiązać problemy dotąd zbyt skomplikowane. Problemy, dla których ręcznie pisanie reguł było trudne, a wręcz niemożliwe. Problemy tego świata, które mogę dzięki temu rozwiązywać to np.
- sprawdzanie, czy dana transakcja kartą kredytową nie jest oszustwem,
- przewidywanie cen mieszkań na rynku,
- przewidywanie, którzy klienci zrezygnują z moich usług,
- rozpoznawanie kotków i piesków na zdjęciach,
- automatyczne walidowanie zdjęć paszportowych.
– Już rozumiem. Czyli uczenie maszynowe to w zasadzie odwrócenie standardowego paradygmatu programowania, gdzie informacjami wejściowymi do algorytmu były dane i reguły, które dawały odpowiedzi. W tym machine learningu to dane i odpowiedzi są wejściem, a reguły wyjściem, tak?
– 😲
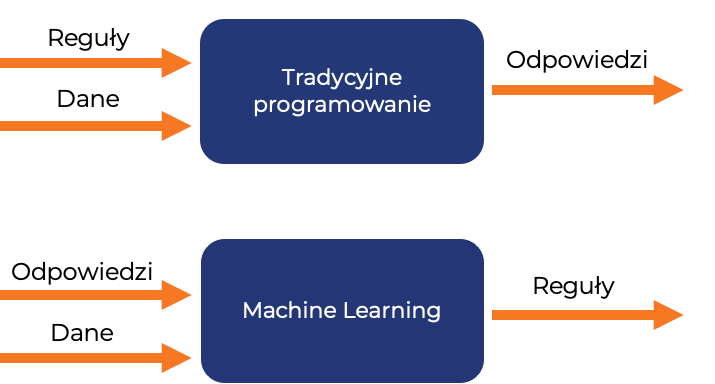
Machine Learning zmienia standardowe podejście do tworzenia oprogramowania, gdzie pisze się kod, który następnie przyjmuje dane wejściowe i zwraca odpowiedź. W uczeniu maszynowym karmimy nasz model danymi i odpowiedziami, a model uczy się, czyli buduje reguły.
Kiedy uznamy, że nasz model jest wystarczająco “nauczony”, tzn. zbudował reguły dające odpowiedzi wystarczająco odzwierciedlające nasze oczekiwane rezultaty, możemy z niego korzystać, czyli otrzymywać odpowiedzi dla danych, których nie widział podczas treningu (tzw. inferencja (?), z ang. model inference).
“Ty, a co to ten Machine Learning? Jak to działa?” – wyjaśnienie Uczenia Maszynowego dla osób bardziej technicznych
Stałem przy ekspresie do kawy. Piątek – czyli prawie weekend. Kolega z pokoju obok, który akurat przechodził, zagaił pytaniem podobnym do tego z nagłówka: “jak działa machine learning? Jak wy tam uczycie te maszyny? Ty coś robisz czy tylko siedzisz i patrzysz?”

Najprościej pracuje się na przykładach, prawda? Spójrzmy więc na przykład.
Jest sobie Taki Michał. Michał, jako administrator sieciowy, chce chronić użytkowników poczty przed spamem, bo nikt nie lubi spamu, prawda? Michał mógłby ręcznie napisać pewne reguły, jak:
- Jeżeli w treści znajdziesz “viagra” – spam.
- Jeżeli w treści znajdziesz “King of Nigeria” – spam.
- Jeżeli w treści znajdziesz “Potwierdzenie(…) przesyłki (…) załącznik(…)” – prawdopodobnie spam.
- itd.
Michał jednak wie, że komputery mogą się uczyć, bo jest coś takiego jak uczenie maszynowe. Przygotował więc pewien zbiór maili – na podstawie zgłoszeń od użytkowników, własnej pracy, list dostępnych w internecie. Część z wiadomości oznaczone jest jako spam, część jako „czyste” wiadomości.
Definicja formalna
Jak sama nazwa wskazuje – Uczenie Maszynowe – mamy maszynę, która się uczy na podstawie danych. Tak też, już w latach 60 zdefiniował ten termin Arthur Samuel:
Uczenie maszynowe daje komputerom możliwość „uczenia się” bez bycia konkretnie zaprogramowanym do danego zadania.
Arthur Samuel, 1959
Lub bardziej technicznie, “inżyniersko”:
Program komputerowy uczy się z doświadczenia E (Experience) w kontekście pewnego zadania T (Task) i miary wydajności P (Performance), jeżeli jego wydajność na T, mierzona P, wzrasta wraz z doświadczeniem E
Tom Mitchell, 1997
Michał może wybrać sobie pewien algorytm uczenia maszynowego (o takich algorytmach opowiemy sobie w innym wpisie), który jako wejście otrzyma wiadomości i etykietę SPAM / NIE-SPAM i na tej podstawie, będzie się uczył. Nie wnikamy na razie w jaki sposób. Innymi słowy, Michał trenuje algorytm w kontekście zadania T – oznacz nowy e-mail jako spam, mając doświadczenie E – treningowy zbiór oznaczonych maili, sprawdzając skuteczność tego modelu jako procent poprawnie oznaczonych e-maili jako spam – miara P. I ot, cały Machine Learning. Prawie cały 😉
Co wchodzi, co wychodzi – o typach systemów uczenia maszynowego
Michał, szukając odpowiedzi na pytanie czym jest machine learning, dowiedział się, że zanim zacznie swoją przygodę z uczeniem maszynowym, musi sobie odpowiedzieć na jedno bardzo, ale to bardzo ważne pytanie: jakie będą dane wejściowe do jego systemu, w jaki sposób chce uczyć i co chce otrzymać na wyjściu? Dobra odpowiedź na to pytanie pozwala na wybranie odpowiedniej drogi.
Michał podczas buszowania po sieci natknął się na pojęcia uczenia nadzorowanego i nienadzorowanego. O co chodzi? Czy to wszystkie rodzaje?
Tutaj dygresja: Temat danych w kontekście uczenia maszynowego jest głęboki jak Rów Mariański i szeroki jak wachlarz ofert pracy na Lubelszczyźnie. Poruszymy go w osobnym wpisie na tym blogu. Tutaj skupimy się na informacjach, na jakie natrafił Michał wyszukując “typy uczenia maszynowego.”
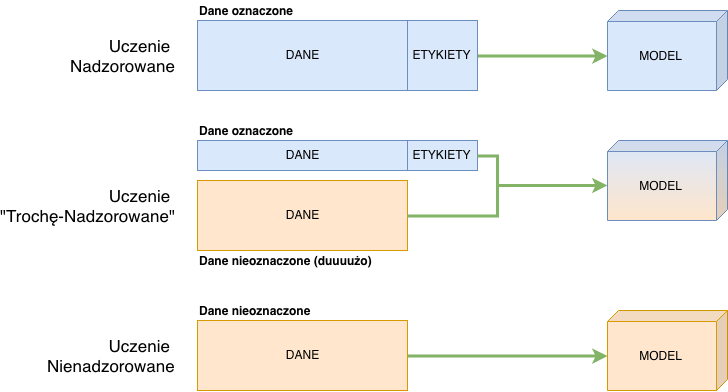
Uczenie nadzorowane (Supervised Learning)
Bardzo często wykorzystywane podejście, które samo ładnie się przedstawia – nadzorujemy sposób, w jaki nasz algorytm się uczy.
Wejściem do naszego algorytmu jest oznaczony zbiór danych (treningowych) tzn. taki, w którym każdemu “wierszowi” danych (sample, example) przyporządkowana jest etykieta – czyli wartość, którą chcemy otrzymać na wyjściu naszego algorytmu – nasza odpowiedź. Mamy więc pary: rekord danych – etykieta.

Poniżej są przykłady, dzięki którym Michał zrozumiał zagadnienie. Spójrz na nie, proszę:
- zdjęcie ma przypisaną klasę (np. kot, pies, szynszyla krótkoogonowa);
- tekst ma etykietę określającą sentyment (np. pozytywny, negatywny, neutralny);
- rekord opisujący mieszkanie ma przypisaną cenę – tak, dokładnie, cenę; docelowa wartość to wcale nie musi być etykieta czy kategoria (wartość dyskretna) – może to być wartość liczbowa ciągła;
- itd.
Przykładem takiego uczenia jest również problem Michała: klasyfikacja maili na: spam i nie-spam. Innym przykładem może być przewidywanie (predykcja) ceny samochodu na podstawie informacje zebranych z ogłoszeń z serwisów ogłoszeniowych.
Uczenie nienadzorowane (Un-supervised Learning)
Drugie wykorzystywane podejście to uczenie nienadzorowane. Jak działa? Jak pewnie zgadłeś, nasz wejściowy zbiór danych nie ma etykiet – nie narzucamy wartości, jakie chcemy otrzymać na wyjściu.
Są to techniki uczenia maszynowego, które same szukają w danych pewnych zależności czy wzorców. Zostawiamy algorytm samemu sobie, aby podczas procesu uczenia znalazł w danych interesujące struktury.
“Maszyno – ucz się sama!”, można by rzec. Ucz się sama, bez bezpośredniego wskazania czy masz rację, czy się mylisz. W zasadzie dopiero w przypadku stosowania uczenia nienadzorowanego do wszelakich zadań będziemy mogli mówić o “prawdziwym AI” – tak przynajmniej twierdzi pan Yan Lecun, Director of AI Research w Facebook.
Przykład: mamy bardzo dużo informacji o użytkownikach naszej strony internetowej. Możemy na tych danych uruchomić algorytm grupowania (inaczej analiza skupień, klasteryzacja, ang. clustering), który podzieli odwiedzających na pewne podobne grupy. Czy musimy wskazać jak ma dzielić? Nie, algorytm sam wyszukuje pewne połączenia czy korelacje w danych i na tej podstawie zwraca wynik. Skutkuje to tym, że wynik taki musimy przeanalizować we własnym zakresie. To my musimy te grupy później jakoś “nazwać”.
Uczenie “Trochę-Nadzorowane” (Semi-supervised Learning)
To kombinacja podejść 1. i 2., ponieważ w tym przypadku używamy do uczenia zarówno danych oznaczonych (małej porcji) jak i nieoznaczonych (dużej porcji). Model uczy się na podstawie oznaczonych informacji. Następnie, na podstawie tego, czego się nauczył, oznacza sobie dane jeszcze nieoznaczone. Potem następuje faza uczenia na całym komplecie danych, bo są one już oznaczone. O dziwo, daje to całkiem niezłe rezultaty.
Przykładem takiego rozwiązania mogą być rozwiązania chmurowe do przechowywania zdjęć, np. Google Photos. Kiedy wrzucimy zdjęcia do tej usługi, wykrywa ona twarze na zdjęciach. Następnie pyta się nas: “Hej, a ta uśmiechnięta buzia tutaj to kto?”. Wystarczy, że oznaczymy taką osobę na jednym zdjęciu, a usługa sama wskaże nam inne zdjęcia, na których ta osoba jest (oczywiście w idealnym świecie, często trzeba oznaczyć osobę na kilku zdjęciach, osoby są mylone, itp. Ale co do zasady – to się zgadza 🙂 )
Uczenie Ze Wzmocnieniem (Reinforcement Learning)
Bardzo efektownym rodzajem uczenia maszynowego jest Uczenie Ze Wzmocnieniem (ang. Reinforcement Learning). Efektownym, bo często wykorzystywanym do pokonywania ludzi w przeróżnych grach: planszowych, jak AlphaGo grające w Go, czy komputerowych jak OpenAI Five grające w DOTA, AlphaStar – w StarCraft II czy DQN grającego w retro-gry na Atari. Tego typu machine learningu używa się również w innej bardzo widowiskowej dziedzinie – robotyce. Na czym polega reinforcement learning?
W uczeniu ze wzmocnieniem mamy do czynienia z Agentem, który w danym momencie podejmuje akcje na podstawie obserwacji środowiska. Za każdą podjętą akcję, jest nagradzany (lub karany). Celem agenta jest uzyskanie jak największego (maksymalizacja) współczynnika nagrody. Współczynnika, który określony jest odgórnie i zmusza agenta do wyszukiwania ścieżki decyzji, którą powinien (wg nadzorującego) obrać w danej sytuacji. Strategia ta definiuje jaką akcję agent powinien podjąć, gdy jest w danej sytuacji.
Wejściem do naszego algorytmu jest pewien początkowy stan, od którego model startuje. Podczas procesu uczenia algorytm podejmuje decyzje i jest za nie nagradzany lub karany. Wyjść z algorytmu jest bardzo dużo, ponieważ każdy problem można rozwiązać na wiele sposobów. Najlepsze rozwiązanie wybierane jest na podstawie maksymalnej nagrody.

Czy Supervised Learning i Reinforcement Learning to to samo?
Z opisu wygląda podobnie do uczenia nadzorowanego, wszak mówimy algorytmowi, kiedy popełnił błąd, a kiedy się mylił. Różnica pomiędzy nimi jest jednak istotna. W uczeniu nadzorowanym decyzja jest podejmowana dla każdej próbki wejściowej oddzielnie, stąd też nasza etykieta przypisywana jest każdej pojedynczej danej wejściowej. W przypadku Reinforcement Learning – mamy do czynienia z sekwencją decyzji i to im nadajemy etykiety. Wyjście w danym kroku zależy od obecnego stanu i wyjścia z poprzedniego kroku.
Reinforcement learning wykorzystuje na przykład wspomniany na początku AlphaGo, które to uczyło się zwycięskich reguł poprzez analizę milionów innych gier, a także spędzając godziny na graniu samo ze sobą. Dzięki temu, w 2017 roku, pokonało ówczesnego mistrza świata w Go. Warto wspomnieć, że podczas pojedynku z mistrzem uczenie było wyłączone – AlphaGo korzystało jedynie z reguł wyuczonych wcześniej.
Dlaczego używać uczenia maszynowego?
Swój problem Michał może rozwiązać korzystając z tradycyjnego podejścia – znaleźć pewne zależności i napisać zbiór reguł, dzięki którym jego program będzie zwracał pewien rezultat. Już na pierwszy rzut oka widać tutaj duży problem: dla rzeczywistych zastosowań taki zbiór reguł zazwyczaj jest bardzo skomplikowany. Jego przygotowanie, a później utrzymywanie, to spore wyzwanie. W niektórych przypadkach – prawdopodobnie nie będzie nawet możliwe, bo środowisko, w którym pracuje program, ciągle się zmienia lub reguł jest po prostu za dużo.
Uczenie maszynowe doskonale sprawdza się w przypadkach, gdy:
- tradycyjne rozwiązania wymagają bardzo dużo ręcznego przygotowywania skomplikowanych reguł – uczenie maszynowe pozwala na uproszczenie kodu i zazwyczaj osiągnięcie lepszych rezultatów;
- mamy bardzo złożone problemy, dla których nie istnieje „tradycyjne” rozwiązanie;
- poruszamy się w zmieniającym się środowisku – systemy wykorzystujące ML potrafią się dopasowywać, gdy napływają nowe dane;
- w przypadku gdy szukamy informacji w dużych i skomplikowanych zbiorach danych;
Do czego używać uczenia maszynowego?
Uczenie maszynowe ma ogromne spektrum zastosowań. Wystarczy chociażby zerknąć na zestawienie na stronie appliedAI.com, gdzie jest wymienionych ponad 100 możliwości w różnych dziedzinach. A i to nie jest wyczerpująca lista. Część zastosowań mogłeś / mogłaś zobaczyć patrząc na przykłady podane w każdym z podpunktów dotyczących poszczególnych typów uczenia maszynowego, a jeżeli szukasz dalszych inspiracji, polecam stronę podaną powyżej.
Bibliografia

Część przykładów i opisów została zaczerpnięta z książki Auréliena Gérona: Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems. Polecam serdecznie na początek przygody z Machine Learningiem.
Kadry na początku pochodzą z filmu“Lśnienie” Stanleya Kubricka
Postscriptum
Michał, o którym była opowieść, tak na prawdę… nie istnieje! SZOK! 🙂 Zdjęcie zostało wygenerowane na stronie http://thispersondoesnotexist.com, która używa sieci GAN do generowania realistycznych zdjęć osób. Osób, które nie istnieją 🙂 Więcej o sieciach GAN napiszę w osobym wpisie.
Jeżeli miałbyś jakieś pytania lub uwagi, zapraszam do komentowania wpisu lub skorzystania z zakładki kontakt – odpowiadam na każdą wiadomość 🙂

![[#w3linijkach] Jak pobrać dane z MySQL i zapisać do CSV w Pythonie?](https://uczymymaszyny.pl/wp-content/uploads/2021/05/andrzej-to-jebnie-340x227.jpg)

{kind=link}
Najs:) Czekam na kolejne wpisy:)
Mega!
Sam od jakiegoś czasu interesuję się ML, chętnie zajrzę do Twojego bloga.
Czy w przyszłości będziesz podejmować próbę pokazania przykładów np. reinforcement learning?
Szczególnie interesujące wydaje mi się uczenie ze wzmacnianiem połączone z głębokimi sieciami rekurencyjnymi 😀
Liczę, że i o tym coś napiszesz 😀
Dzięki wielkie Paweł!
W przyszłości pewnie tak, natomiast na ten moment będziemy powoli, kroczek po kroczku, zagłębiać się w świat Machine / Deep Learningu 🙂
Pozdrawiam,
Konrad
Dzięki Konrad1 Krótko, zwięźle i na temat.
“Co więcej, często termin ten jest mieszany lub używany zamiennie z wyrażeniami Sztuczna Inteligencja (Artificial Intelligence, AI), Data Science czy Głębokie Uczenie Maszynowe (Deep Learning). ”
Jaka jest odpowiedz na to stwierdzenie? Czy Reinforcement Learning to wlasnie AI?
Dzięki Kuba za komentarz!
To jest bardzo dobre pytanie, ale niestety odpowiedź nie zmieściła się już w tym i tak nieco długim artykule 🙂
Na pewno powstanie o tym osobny post.
A tak w skrócie to chyba poniższy obrazek to dobrze podsumowuje.

I odpowiadając na ostatnie pytanie, to RL jest jedną z technik Machine Learning, która może służyć do tworzenia rozwiązań “inteligentnych” (AI).
Czekam z wypiekami na twarzy na następny artykuł!! (Upały trochę są współwinne wypieków ;] )
Dzięki. Kolejny in progress, dam znać 🙂
Super. Ale kiedy ten kolejny odcinek? 😀
Jerry, już blisko, na dniach robimy cutover na produkcję 😉
Opisane prosto i w praktyczny sposób. Nawet taki laik jak ja ogarnął o co chodzi. Do tego napisane “z jajem”. Tak trzymaj, czekam na więcej 🙂
Bardzo dobry artykul, przystepnie wytlumaczony temat. Mam do Ciebie pytanie troche bardziej do podstaw algorytmow zobasz jakies dobre materialy zeby powtorzyc matematyke zeby lepiej zrozumiec algorytmy ML?
Dzięki Grzegorz! Odnośnie matematyki pod ML, to ja akurat w żadnym kursie nie uczestniczyłem (miałem te rzeczy na studiach, wystarczyło odświeżyć), ale słyszałem dobre opinie o kursie od Stanforda i MIT. Ewentualnie jeżeli będziesz przechodził kurs Andrew Ng to on też fajnie tłumaczy poszczególne zagadnienia, nie zagłębiając się bardzo mocno w szczegóły, ale wystarczająco do zrozumienia tematu.
Cześć,
mieliśmy przyjemność porozmawiać na Social Media i właśnie znalazłem chwile, by zagłębić się w Twoich wpisach.
Jestem pod wrażeniem płynności z jaką poruszyłeś zagadnienie uczenia maszynowego.
Tak trzymaj! 🙂
Pozdrawiam, Mateusz.
Dzięki Mateusz! Jako, że jesteśmy na przełomie roku, to mam nadzieję, wróć, wiem!, że w 2020 powstanie o wiele więcej wpisów, niż w 2019. Między innymi patrząc na Twoją działalność widzę, że łączenie pracy i blogowania nie jest żadną wymówką do niepublikowania, jak to do tej pory było u mnie 😉
Cześć Konrad,
Fajnie wytłumaczyłeś to czym jest ML. Zastanawiam się jak to wygląda w kodzie. Jeszcze nie programowałem żadnego swojego modelu do ML więc nie mam bladego pojęcia jak to wygląda.
Widziałem jednak na Youtube przykłady Reinforce ML, jak komputer grał w grę typu Flappy Bird i z generacji na generację był coraz lepszy. Czy nie pomyliłem tu pojęć?
W ogóle czym się różni programowanie oparte na algorytmach ewolucyjnych od ML?
Jak coś pomyliłem to proszę popraw mnie. ML jest dla mnie nowością.
Pozdrawiam :-).
Mateusz, wszystko się zgadza, ten Flappy Bird to przykład Reinforcement ML.
Co do Algorytmów ewolucyjnych vs ML, to tutaj algorytmy ewolucyjne zaczynają z pewną randomowo wygenerowaną populacją (zbiorem rozwiązań) i wykorzystując pewne heurystyki podpatrzone w przyrodzie wyszukują zbiór przydatnych rozwiązań. W przypadku reinforcement ML mamy agenta, który wykonuje pewne kroki i jest za nie nagradzany lub karany. Czyli mamy pewną z góry określoną funkcję, którą agent musi maksymilizować.
W pewnych kontekstach algorytymy ewolucyjne mogą być używane np w sieciach neuronowych i być pewnego rodzaju formą reinforcement learning, ale działa to trochę inaczej, niż klasyczny RL.
Więcej możesz poczytać tutaj: https://www.researchgate.net/publication/324082363_Reinforcement_learning_versus_evolutionary_computation_A_survey_on_hybrid_algorithms
ewentualnie krótsze
https://www.quora.com/How-is-reinforcement-learning-related-to-genetic-algorithms
https://stackoverflow.com/questions/12411197/can-evolutionary-computation-be-a-method-of-reinforcement-learning
Świetny wpis o uczeniu maszynowym i czym tak właściwie jest. Zarówno do nietechnicznych jak i troszkę. Natomiast przykład podany w postscriptum jest świetny – idealnie pokazuje niedowiarkom, jak to może działać. Chociaż uważam, że tego typu systemy (na podstawie doświadczeń z Google) wciąż są ułomne to z biegiem czasu będą mogły być bardzo pomocne. O ile będziemy pamiętać, że one mają nam pomagać a nie nas wyręczać. Pozdrawiam.