

Jeżeli oglądałeś Grę o Tron to wiesz, że dawno, dawno temu, Targaryenowie zdobyli tron Westeros dzięki dosyć istotnej przewadze. Mieli smoki i umieli z nich korzystać. Uczenie maszynowe w wielu zastosowaniach jest takim smokiem. Odpowiedni model machine learning pomaga rozwiązać problemy, których maszyny do tej pory rozwiązać nie mogły lub miały z tym spore trudności.
Przewidywanie, która winda w najbliższym czasie się zepsuje, detekcja raka skóry, autonomiczne samochody czy sortowanie ogórków. To tylko nieliczne, ale bardzo ważne przykłady zastosowania uczenia maszynowego w prawdziwym życiu.
Chyba warto takiego smoka posiadać w arsenale? Pozwól więc, że pokażę Ci 7 kroków, które należy wykonać, żeby wytrenować maszynę!
A jeżeli jeszcze nie wiesz czym jest machine learning, to zerknij do tego postu.
Ważny jest proces
Ten post nie ma na celu opisania w szczegółach każdego z kroków. Musiałaby powstać książka, a ja książek pisać nie umiem (jeszcze 😉). Chodzi o to, żeby poznać proces. Znając proces możemy każdy z kroków zgłębiać rozwiązując konkretne problemy. Takie “Just-in-time learning”.
Proces ten jest dosyć ogólny i pokazuję drogę “Od zera do pierwszego modela*”, a nie “Od dobrego modelu do świetnego modelu”.

Co nas czeka?
1. Definicja problemu i zbieranie danych
“Data is a new oil” – tak mówią mądrzy ludzie w Internecie i ciężko się z nimi nie zgodzić. Dobre dane są podstawą dobrego modelu.
Dlatego tak ważne jest posiadanie odpowiednich danych. Pewnie w Twojej głowie natychmiast pojawia się pytanie – “Odpowiednich? A dla kogo odpowiednich? Do czego odpowiednich?” I bardzo dobrze, że o to pytasz! Zanim rzucimy się w wir uczenia, musimy sobie odpowiedzieć na pytanie: co my w ogóle chcemy osiągnąć? Musimy zdefiniować problem.
Gdzie idziemy? Dokąd zmierzamy?
Aby odpowiednio zebrać i przygotować dane, musimy wiedzieć, jaki problem rozwiązujemy. Klasyfikacja? Regresja? Klastrowanie? Bez odpowiedzi na to pytanie i określenia, jakie są nasze dane wejściowe i wyjściowe, nie możemy przejść dalej.

Żeby osiągnąć sukces, musimy sobie zdefiniować co rozumiemy przez sukces. Musimy określić, jak zmierzymy, czy doszliśmy tam gdzie chcieliśmy. Metryka, którą wybierzemy, musi być dostosowana do problemu, który nakreśliliśmy. Tych miar może być kilka, bo np. jedna miara będzie bardziej “techniczna”, za to inna będzie interesować klienta, któremu dostarczamy rozwiązanie.
Jakość i ilość danych – od tego zależy jak dobry model można stworzyć
Kiedy wiemy już co chcemy osiągnąć, musimy dane zebrać. Ten krok jest ważny, ponieważ od jakości i ilości danych, które zgromadzimy, zależy jak dobry model możemy później stworzyć. Jak mówi stare, chińskie przysłowie:
”Garbage In – Garbage Out”
Konfucjusz (chyba)
Dane Schrödingera
Określiliśmy problem, zebraliśmy dane. Wydaje się nam, że możemy przejść dalej. Na tym etapie zakładamy dwie hipotezy:
- Przy pomocy naszych danych wejściowych jesteśmy wstanie przewidzieć dane wyjściowe
- Zebrane dane mają wystarczająco dużo informacji, żeby na ich podstawie nauczyć się relacji pomiędzy wejściem a wyjściem
Jednak dopóki nie będziemy mieli działającego modelu, nie jesteśmy w stanie stwierdzić, czy powyższe jest prawdą. Idźmy więc dalej, bo jak inaczej się o tym przekonamy?
2. Przygotowanie, czyszczenie danych
– “Jak wygląda Twój dzień pracy?”
To pytanie często można spotkać w internetowych dyskusjach. Często mamy jakieś postrzeganie świata i ciekawi nas, jak może wyglądać życie innych ludzi. W przypadku Data Scientistów większość z nich twierdzi, że 80% ich czasu to przygotowanie i czyszczenie danych.
“Co?! Przecież to proste. Stary, dane to dane. SELECT * FROM table i już.”
Zapewne w idealnym świecie ludzie dbają o “czystość” i “kompletność” danych. Jednak w świecie rzeczywistym dane, które otrzymujemy, są zazwyczaj dalekie od ideału…
Eksploracja danych
W znakomitym poście na temat trenowania sieci neuronowych Andrej Karpathy zatytuował jeden z podpunktów
“Become one with the data”
Andrej Karpathy
I to jest dokładnie to, co w tym kroku powinniśmy zrobić. Powinniśmy szczegółowo, wnikliwie i dokładnie zapoznać się z danymi, które posłużą nam do ujarzmienia maszyny.
Czyszczenie, formatowanie, standaryzowanie
W danych może brakować niektórych wartości, mogą się znaleźć uszkodzone obrazy czy literówki. Dane mogą być niezbalansowane, co może mieć ogromny wpływ na wyniki procesu trenowania. Być może trzeba je w pewien sposób zbalansować? Być może trzeba je zestandaryzować? Czy w danej kolumnie faktycznie potrzebujemy dokładnej wartości, czy możemy pogrupować dane w jakiś sposób? Czy my w ogóle mamy wszystkie potrzebne cechy (features)? Czy to co mamy wystarcza, czy potrzebujemy szerszego kontekstu? Czy …

Na większość z tych pytań trzeba sobie odpowiedzieć, zanim rzucimy się w bój trenowania modelu. Im więcej energii poświęcimy na dobre przygotowanie danych, tym łatwiej nam będzie na późniejszych etapach analizować postępy i, co może ważniejsze, błędy.
Ten krok jest to tak samo ważny w “klasycznym” uczeniu maszynowym, jak i w przypadku używania sieci neuronowych, bo jak napisał Andrej w powyżej podlinkowanym artykule, parafrazując:
“Sieć neuronowa jest pewnego rodzaju skutecznie skompresowaną / skompilowaną wersją twojego datasetu. Jeżeli znasz dane, to będziesz w stanie popatrzeć na (błędne) predykcje i zrozumieć, skąd mogły się wziąć. Dodatkowo, jeżeli sieć zwraca wyniki, które nie są zgodne z tym, co widziałeś w danych, to wiesz, że coś jest nie tak.”
Bardzo dobrym sposobem jest też odpowiednie wizualizowanie danych, patrzenie na rozkłady, czy szukanie punktów odstających (outliers), które często są nam w stanie odkryć błędy w danych czy ich przygotowaniu.
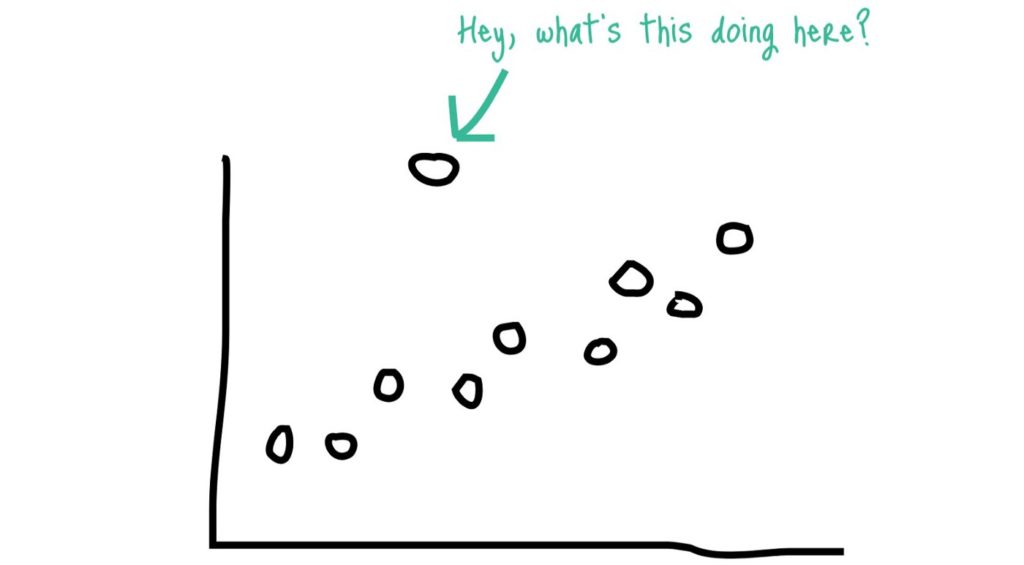
Brzmi to skomplikowanie, ale nie przejmuj się! Jak mówi przysłowie, nie od razu King’s Landing zbudowano (czy jakoś tak).
Przygotowanie danych wymaga wprawy i z każdym kolejnym zbiorem danych wyrabia się pewna intuicja. Część z tych wątpliwości rozwiejemy na pewno w jednym z kolejnych postów, który będzie dotyczył przygotowywania danych.
Podział na zbiory
Ten krok jest dosyć istotny i na pewno powstanie na ten temat osobny post. Na ten moment musimy sobie powiedzieć, że nasze dane dzielimy na co najmniej dwa, a czasem trzy podzbiory
- Treningowy (Train)
- Walidacyjny (lub Developerski / Dev)
- Testowy (Test)
Pierwszy ze zbiorów będzie używany do trenowania naszego modelu. Powinien on zawierać większość dostępnych danych. Często spotykanym podziałem jest 70% – 90% na trening i odpowiednio 30% – 10% na test / walidację. W przypadku bardzo dużych ilości danych te proporcje mogą być zupełnie inne (nawet 99% / 0.5% / 0.5%)[1], ale to temat na dłuższe rozważania.

– Ale komu to potrzebne? A dlaczego?
A no wyobraź sobie, że uczysz się do testu. Dostajesz listę pytań, które masz opanować. Przychodzi czas egzaminu, dostajesz kartkę, z drżeniem serca otwierasz arkusz i… TE SAME PYTANIA! Mama szykuj kompot, będziemy świętować!
Po egzaminie idziesz do pracy, gdzie masz się wykazywać wiedzą zdobytą wcześniej w codziennych zadaniach. No i okazuje się, że tam nie dostajesz pytań z opracowanych zagadnień, tylko z dużo szerszego zakresu. Czy ten egzamin też zdasz na 5.0?
Tak samo jest z modelem. Jeżeli chcemy sprawdzić (chociaż lepiej by było powiedzieć “zasymulować”), jak nasz zuch poradzi sobie z napływającymi w przyszłości przykładami, musimy go sprawdzać na danych, których nie używaliśmy do treningu. Na danych, których model “nie widział”.
Po to są nam dwa zbiory. Jeden do nauki, a drugi do egzaminu.
3. Wybór modelu
Mamy dane! Nastał ten piękny moment, gdy możemy zabrać się za ten cały machine learning a nie jakieś NaNy, puste wiersze i brakujące kolumny. No to nauczmy model! Ale który?
Część jest dobra do jednego typu zadań, a część do innego
Obecnie częstym podejściem jest: róbmy Deep Learning! Nie ważne co, nie ważne po co, DEEP LEARNING! Jak mawia mój kolega Radek, “Hop siup hyc na krowę i jedziemy!”.

Hola hola, wstrzymajcie swoje konie (i smoki). A jaki w ogóle problem chcemy rozwiązać?
Dobrym podejściem jest: zaczynaj od najprostszych. Czy korzystasz z algorytmów machine learning, czy Twój problem wymaga użycia sieci neuronowych – zaczynaj od najprostszych metod.
Zawsze zaczynaj od najprostszych.
Dlaczego? Bo może się okazać, że te 30 minut które poświęcisz na uruchomienie prostej regresji liniowej, drzewa decyzyjnego, czy podstawowej sieci uważanej za state-of-the-art w danym zadaniu, zaoszczędzi Ci mnóstwo czasu, który poświęciłbyś na szukanie wymyślnego algorytmu uczenia maszynowego czy budowaniu skomplikowanej głębokiej sieci neuronowej.
Istnieje wiele różnych modeli wymyślonych przez mądrych ludzi
Często zanim rzucimy się w wir pracy warto podpytać u wujka Google, czy przypadkiem ktoś już nie wpadł na rozwiązanie problemu podobnego do naszego. Społeczność wokół Machine / Deep Learning jest bardzo otwarta i bardzo chętnie dzieli się swoimi dokonaniami. Warto więc zajrzeć na takie strony, jak:
czy po prostu dobrze “pogooglać”. Github, konferencje czy publikacje naukowe to źródło nieskończonej ilości wiedzy, która bardzo często jest łatwo stosowalna do naszych praktycznych zastosowań.
4. Trening
– Co mówi Batman do Robina, gdy chce, żeby ten wsiadł do Batmobilu?
– ………
– Wsiadaj, Robin!
Wsiadamy więc do Batmobilu i trenujemy nasz model. Zależnie od wybranego modelu, języka, framework’a, etap ten wygląda różnie, ale pewne elementy są stałe dla wszystkich środowisk.
Pewnie pamiętasz, że nasz dataset jest podzielony na zbiory treningowy i ewaluacyjny (ewentualnie testowy)? Patrząc z lotu pingwina (pozdrawiam Wojtek!), proces treningu polega na pokazaniu algorytmowi danych ze zbioru treningowego, aby na ich podstawie mógł zbudować pewne reguły wykorzystując do tego pewną funkcję straty. A funkcje straty, mogą być różne i powinny być dobrane do problemu i miary sukcesu, którą to określiliśmy sobie na początku naszych zmagań. Bo zrobiliśmy to, prawda?
Równym krokiem przez epoki
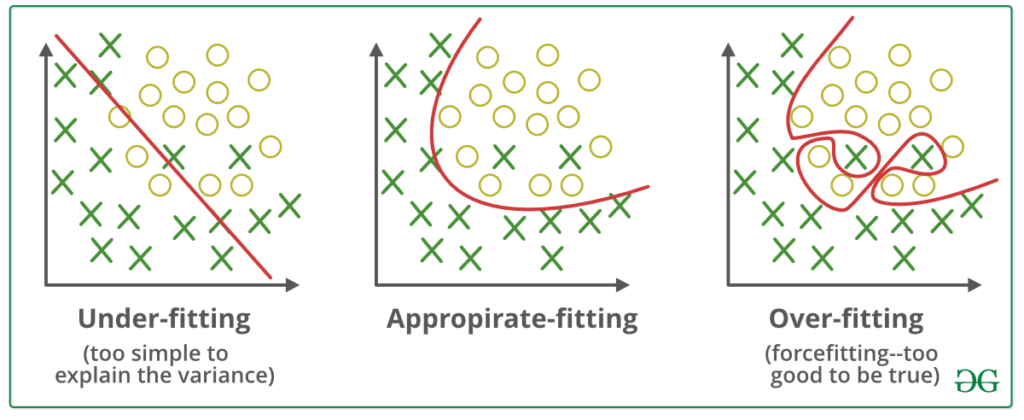
Wykonując krok uczenia, dane możemy pokazywać pojedynczo (rekord po rekordzie, zdjęcie po zdjęciu) lub w większych “paczkach”. Wielkość takiej paczki to tzw. batch size. Gdy pokażemy wszystkie dane ze zbioru treningowego to zakończy się epoka. Wtedy to zazwyczaj dokonujemy pierwsze ewaluacji – sprawdzamy jakie rezultaty (wartość wybranej metryki oraz błędu) osiągamy na danych ewaluacyjnych (te, których model nie widział). Dzięki temu wiemy, jak nasz model generalizuje, czy się przeuczył (overfitting) bądź nie douczył (underfitting).
5. Ewaluacja
Gdy nasz algorytm uczył się już przez określoną przez nas liczbę epok, dokonujemy końcowej ewaluacji. Sprawdzamy nasz wyjściowy model na zbiorze walidacyjnym przy pomocy wybranej metryki (bądź metryk).
Ważne jest, że ewaluacja musi nastąpić na danych, które nie były używane do uczenia. Danych, których model “nie widział”. Tak wiem, powtarzam się. Ale tylko w ten sposób jesteśmy w stanie sprawdzić jak nasz model może zachowywać się dla “rzeczywistych przypadków” – czyli jak generalizuje (tutaj oczywiście sporo zależy od tego, czy mamy “dobre dane”, ale to trzeba usiąść na spokojnie…).
6. Optymalizacja Hiperparametrów
Mamy już wykonaną pierwszą ewaluację. Wiemy, jak wygląda nasza metryka i jak daleko jesteśmy od naszego celu, który sobie wstępnie ustaliliśmy na początku naszej drogi. Czas na “pokręcenie gałkami na tablicy rozdzielczej” – czyli Optymalizację Hiperparametrów.

Ten krok, oprócz obrabiania danych, jest drugim najbardziej czasochłonnym. Modyfikujemy hiperparametry, trenujemy, ewaluujemy, znowu modyfikujemy, trenujemy, ewaluujemy i tak w koło Macieju, aż dojdziemy do miejsca w którym uznamy, że jesteśmy tam, gdzie chcieliśmy (albo nie jesteśmy w stanie nic więcej ugrać i musimy zacząć od początku – bywa…).
Co to są hiperparametry?
Każdy z algorytmów uczenia maszynowego ma pewne parametry których uczy się z danych. Jest to podstawowe założenie uczenia maszynowego – dopasować model do danych.
Istnieją jednak parametry “wyższego rzędu”, których model nie może “nauczyć się” z danych. Sterują one zachowaniem modelu podczas uczenia. Są one ustawiane przez nas przed treningiem, aby wskazać pewne cechy samego treningu (np. jak skomplikowany ma być model, jak szybko ma się uczyć, itp.)
W tym miejscu nie jesteśmy w stanie ich wszystkich opisać, ale kilka przykładów znajdziesz poniżej:
- liczba drzew w lesie losowym,
- liczba warstw w sieci neuronowej,
- maksymalna głębokość drzewa decyzyjnego,
- parametry jądra w przypadku Support Vector Machines,
- learning rate, czyli jak duże kroki ma robić algorytm podczas uczenia metodami spadku gradientu,
- …
Jak dobrać hiperparametry?
Przy pierwszej iteracji jest to często kwestia pewnej intuicji, którą wyrabia się w czasie. Czy odpowiednio je dobraliśmy? Tego dowiadujemy się dopiero po wykonaniu ewaluacji.
Istnieją różne formy pewnej automatyzacji tego procesu. Mamy takie metody jak Grid Search czy Random Search. Zadajemy im pewną przestrzeń parametrów, która ma zostać sprawdzona, oraz miarę, która ma posłużyć do wyboru najlepszych parametrów, a w odpowiedzi otrzymujemy hiperparametry, które zostały wybrane jako najlepsze.
Definition Of Done – kiedy nasz model jest wystarczająco dobry
Musimy sobie ustalić pewne Definition of Done. Przyjemy pewne założenie, kiedy nasz model jest wystarczająco dobry i możemy pierwszą jego wersje pokazać światu. Jeżeli nie robimy konkursu na kaggle, to raczej nie będzie nam zależeć na każdej mikrotysięcznej zmianie naszej metryki.
Częściowo powinniśmy przyjąć jakieś założenia już na początku (bo zdefiniowaliśmy problem, prawda?). Na tym etapie wiemy już, czy nasz model jest w stanie osiągnąć to, co założyliśmy.
7. Predykcje
Mamy wytrenowany model. Czas wsiąść na smoka i zawładnąć królestwem wolnego rynku rozwiązań machine learningowych!
Model w niektórych przypadkach trzeba jeszcze odpowiednio dostosować, aby był gotowy do generowania predykcji dla nowych danych. Czasem możesz się spotkać z terminem inferencji (ang. Inference) – to właśnie “odpytywanie” modelu o jego predykcję dla nowych danych.
Użycie danych do odpowiedzi na pytania
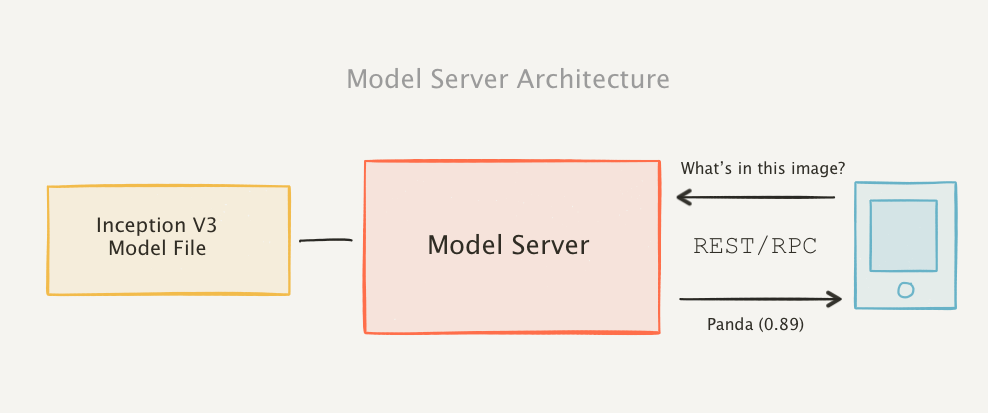
Możemy uraczyć świat naszym modelem na kilka sposobów. Jednym z częściej używanych rozwiązań jest udostępnienie modelu w formie Rest API bądź podobnego serwisu, do którego możemy później wysyłać zapytania w celu otrzymania predykcji dla przekazanych danych. Istnieją gotowe rozwiązania, które ułatwiają “serwowanie” modeli dla użytkowników. Przykładową listę możecie znaleźć w tym artykule.
Co dalej?
Teoria teorią, ale co dalej? Ano dalej będzie… jeszcze więcej teorii! Ale poprzemy ją kodem.
A w następnym odcinku pokażemy sobie na prostym przykładzie jak wytrenować przykładowy model. Będziemy szli z duchem, o którym mniej więcej mówi Jeremy Howard, twórca kursów na platformie fast.ai – napiszmy kod, a później zobaczymy, jak to dokładnie działa 🙂
Bibliografia
- Francois Chollet, Deep Learning With Python, rozdział 4.5 -The universal workflow of machine learning. Choć jest to napisane bardziej w kierunku Deep Learningu, to i tak oddaje podobny flow.
- Yufeng G, The 7 Steps of Machine Learning
[1] Za Andrew Ng, kurs Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization, Week 1, Train / Dev / Test sets
* użycie celowe, “modelu” się nie rymowało…

![[#w3linijkach] Jak pobrać dane z MySQL i zapisać do CSV w Pythonie?](https://uczymymaszyny.pl/wp-content/uploads/2021/05/andrzej-to-jebnie-340x227.jpg)

Dzięki, czekam na kolejne odcinki z przykładowym kodem 🙂
Zaledwie po 7 miesiącach mogę z dumą powiedzieć „Oto jestem”! Jest już post z kodem 😉
https://uczymymaszyny.pl/moj-pierwszy-model-machine-learning/