

Też macie takiego kolegę, który czasem ściąga kurtkę, podaje wam i mówi: “Pa tera co się będzie działo!”? Ja mam. Kończy się to różnie. Czasem śmiesznie, czasem wyśmienicie a czasem na Izbie Przyjęć. To trochę tak jak model machine learning, tylko inaczej…
W poprzednim odcinku, gdzie było bardziej teoretycznie, zapowiedziałem bardziej praktyczny post, który pokaże jak zacząć przygodę z uczeniem maszynowym. Zaledwie po 7 miesiącach mogę z dumą powiedzieć “Oto jestem”. Tutaj zauważ proszę, że zajęło mi to tylko 7 miesięcy, podczas gdy np. George R.R. Martin pisał “Pieśń lodu i ognia” przez pięć lat. Także widzisz, jak prężnie działam!
Po lekturze tego wpisu, który podąża za krokami przedstawionymi w poprzednim poście, dowiesz się, jak w praktyce trenować model uczenia maszynowego. Ba, nie tylko się dowiesz, ale wytrenujesz model machine learning! Także zakasuj rękawy i “Pa tera!”
0. Środowisko
Język – Python
Będziemy się posługiwać językiem Python. Jeżeli nigdy nie miałeś z nim do czynienia, to jest to pierwsze narzędzie, które powinieneś poznać przed wkroczeniem w świat machine learningu. ALE! Zanim rzucisz się w wir oglądania kursów na Udemy albo przeglądania kursu Pythona u Mateusza (BTW. polecam!), to spróbuj przebrnąć przez ten post. Dlaczego?

Python jest dosyć fajnym do czytania językiem. Jeżeli miałeś w przeszłości do czynienia z jakimkolwiek innym językiem programowania, bez problemu poradzisz sobie ze zrozumieniem przedstawionego tutaj kodu.
IDE – Jupyter Notebook
Aby nie kłopotać się z przygotowaniem całego środowiska, skorzystamy z najszybszego i najprostszego rozwiązania.
W świecie Machine Learning bardzo często używa się Jupyter Notebooków. Jeżeli jeszcze nie wiesz co to jest, to zerknij do Jupyter Notebook QuickStart. Notebook będzie naszym głównym narzędziem wykorzystywanym do “zabaw” z kodem.
Środowisko – Google Colab
Jak wspomniałem, aby nie konfigurować wszystkiego samemu, wykorzystamy Google Colab – darmową platformę, umożliwiającą pracę w notebookach z Pythonem oraz uruchamianie kodu. Python jest językiem interpretowanym, więc możemy sobie uruchamiać poszczególne komórki kodu niezależnie od siebie. Co więcej, na Google Colab mamy dostęp do karty graficznej (GPU), która w przypadku trenowania modeli może przyspieszyć proces X-krotnie.
Podglądanie danych – Pandas
Do eksploracji danych wykorzystamy bibliotekę Pandas. Pandas to dobrze znane w środowisku data science narzędzie pozwalające na szybką i elastyczną manipulację zestawem danych.
Tworzenie modelu – FAST.AI
Model uczenia maszynowego stworzymy dzięki bibliotece fast.ai. Fast.ai bardzo ułatwia proces trenowania modeli, a przy tym pozwala na osiągnięcie bardzo dobrych rezultatów.
To nasz pierwszy model, więc zacznijmy jak najprościej. Idźmy zgodnie z duchem propagowanym przez Jeremy’ego Howarda – jednego z twórców biblioteki Fast.AI
Get straight into the code, start building models
Jeremy Howard
1. Definicja problemu i zbieranie danych
Gdzie najlepiej zacząć? Trenujmy model machine learning, aby rozwiązać jakiś problem. Jaki?
Zdefiniujmy problem
Przypuśćmy, że jesteśmy chemikami – alkoholikami. Albo nie. Nasz kolega, Maciek, jest chemikiem – alkoholikiem. Wróć! Koneserem wina. Chciałby spróbować swoich sił w winiarstwie amatorskim. Jako że Maciek jest chemikiem, jest w stanie zmierzyć pewną liczbę parametrów trunku, który produkuje. Co więcej, jako koneser, jest w stanie przypisać wino do jednej z trzech klas. Na razie nie precyzujemy jakie to klasy. Zakładamy, że kolega wie, co robi.
Chcielibyśmy uchronić Maćka od “konieczności” próbowania każdego wytworzonego przez niego wina. Zbudujemy więc model machine learning, który na podstawie danych chemicznych przypisze wino do jednej z 3 klas. Dzięki temu wina będą skategoryzowane, a Maciek bezpieczniejszy.

Skąd weźmiemy dane?
Nasz kolega jest też szanowanym naukowcem, więc jego dokonania zostały opublikowane na stronie Uniwersytetu Kalifornijskiego w Irvine (UCI). Przynajmniej tak twierdzi. Stamtąd je pobierzemy.
import requests
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data'
data_file = open("./wine.data", "wb").write(requests.get(url).content)Dygresja: warto dodać do zakładek stronę UCI Machine Learning Repository – zawiera spor różnych zbiorów danych, które mogą posłużyć do nauki, testowania, próbowania. Polecam, smacznego!
Jaki problem rozwiązujemy. Klasyfikacja? Regresja? Klastrowanie?
W zasadzie odpowiedzieliśmy sobie na to pytanie odpowiednio definiując problem. Chcemy przydzielić każde wino wyprodukowane i zbadane przez Maćka do jednej z trzech klas: 1, 2 lub 3 (na razie nie ważne, co one oznaczają – zaufaj Maćkowi).
Mamy tutaj do czynienia z problemem (oczywiście oprócz alkoholizmu kolegi) klasyfikacji wieloklasowej (multiclass classification).
Patrząc na powyższe, to model machine learning, jaki chcemy stworzyć, to… Tak, dokładnie, klasyfikator!
Metryka, którą wybierzemy, musi być dostosowana do problemu, który nakreśliliśmy.
Przydzielamy wino do jednej z 3 klas. W przypadku takiego zadania możemy zastosować np. skuteczność (accuracy). Sprawdzamy, dla ilu win poprawnie przyporządkowaliśmy klasę. Na ten moment ta prosta metryka będzie dla nas wystarczająca.
Skuteczność, będzie metryką, którą będziemy optymalizować – będziemy się starali, aby była jak najwyższa. W projekcie machine learning można też określić metryki “zadowalające”, czyli takie, które musimy spełnić, ale nie one są celem optymalizacji. Przykładem może być:
- cały model musi zajmować mniej niż 20 MB pamięci
- predykcja dla jednej próbki danych musi trwać krócej niż opróżnienie kieliszka przez Maćka
Wystarczy że osiągniemy założone wyniki, a z pośród wszystkich modeli które je spełnią, wybierzemy ten z najwyższą metryką, którą optymalizujemy.
To tylko przykłady. W naszym przypadku walczymy tylko o skuteczność. Do boju! Zajrzyjmy do danych.
Jakość i ilość danych – od tego zależy jak dobry model można stworzyć
Kiedy zajrzymy do pliku z danymi zobaczymy, że mamy 178 próbek. Powiedzmy, że tyle udało się zebrać, dopóki nasz kolega chemik nie powiedział, że ma już dość.
A co z ich jakością? Narazie mamy Dane Schrödingera. Czy pozwolą nam wytrenować model?
2. Przygotowanie, czyszczenie danych
W dokumentacji możemy wyczytać, że zbiór ten zawiera następujące informacje o każdym winie:
- Category
- Alcohol
- Malic acid
- Ash
- Alcalinity of ash
- Magnesium
- Total phenols
- Flavanoids
- Nonflavanoid phenols
- Proanthocyanins
- Color intensity
- Hue
- OD280/OD315 of diluted wines
- Proline
Co to za kolumny? Nie mam pojęcia. Maciek wie, ale twierdzi, że jeżeli powie to będzie musiał mnie zabić. Ale z pewnością w głosie oświadcza, że to wszystkie dane, jakie są potrzebne i wszystkie są tak samo istotne. On nie ma czasu na głupoty, więc wszystko co robi ma sens.
Maćku, ufam Tobie. To rzekłszy, zajrzyjmy w końcu do danych.
Możemy teraz wykorzystać Pandasa. Jak wczytać dane z pliku CSV do Pandasa? A konkretniej, jak wczytać dane z CSV do DataFrame, czyli struktury, której w Pandasie używamy dla danych tabelarycznych? Ano korzystając z metody read_csv(), której przekażemy ścieżkę do pliku i jednocześnie poinformujemy, że pierwszy wiersz nie zawiera nagłówka, stąd też nazwy kolumn ma wziąć ze zmiennej attributes.
df = pd.read_csv("wine.data", header=None, names=attributes)Eksploracja danych
Powinniśmy szczegółowo, wnikliwie i dokładnie zapoznać się z danymi, które posłużą nam do stworzenia modelu uczenia maszynowego. Jakie pytania możemy sobie zadać?
Szybkie przypomnienie z poprzedniego artykułu:
- Czy dane są zbalansowane? Czy trzeba je w pewien sposób zbalansować?
- Czy trzeba je zestandaryzować lub znormalizować?
- Czy w danej kolumnie faktycznie potrzebujemy dokładnej wartości, czy możemy pogrupować dane w jakiś sposób?
- Czy my w ogóle mamy wszystkie potrzebne cechy (features)?
- Czy to co mamy wystarcza, czy potrzebujemy szerszego kontekstu?
Niczym wóz, który na akermańskich stepach “nurza się w zieloność i jak łódka brodzi“, zanurzmy się w dane. Spróbujmy znaleźć odpowiedzieć na każde z pytań.
Czy dane są zbalansowane?
Jak się tego dowiedzieć? Musimy policzyć, ile próbek mamy dla każdej z klas. W Pandasie możemy wykorzystać do tego metodę value_counts() na kolumnie z naszymi kategoriami. Funkcja ta zlicza ilość wystąpień każdej unikalnej wartości w danej kolumnie.
df['category'] \ # dla kolumny z przypisanymi klasami
.value_counts() \ # policzmy unikalne wartości
.sort_index() \ # posrotujmy, żeby było ładnie
.plot.bar() # i przedstawmy na wykresie
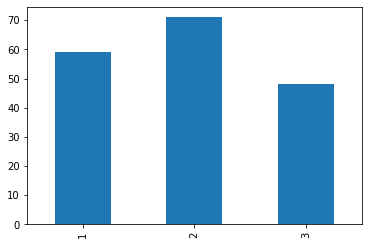
Jak przymkniemy jedno oko, to można powiedzieć, że klasy są w miarę zbalansowane. Zwłaszcza po długotrwałych obradach z Maćkiem. Co dalej?
Normalizacja?
Na początku odpowiedzmy sobie szczerze: czym jest normalizacja danych?
Otóż normalizacja danych zazwyczaj oznacza przeskalowanie wartości tak, że zawierają się w przedziale [0, 1].
Jak w życiu – są plusy dodatnie i plusy ujemne. Dzięki normalizacji operujemy na wartościach dodatnich o tej samej skali, ale tracimy informację o wartościach odstających (outliers).
W bibliotece fast.ai operacja ta jest bardzo prosta. Wystarczy dodać zaimportowaną metodę Normalize do listy metod używanych w preprocessingu. W naszym przypadku wygląda to tak:
preprocessing_steps = [Normalize] Czy w danej kolumnie faktycznie potrzebujemy dokładnej wartości, czy możemy pogrupować dane w jakiś sposób?
O co tutaj chodzi?
Gdybyśmy mieli dane o przedsiębiorstwach, mogłaby tam być kolumna “Lokalizacja”, gdzie mielibyśmy współrzędne geograficzne siedziby danej firmy. Czy dokładne współrzędne są nam potrzebne do uczenia modelu? Być może, ale zamiast tego moglibyśmy tę kolumnę zastąpić kolumnami powiat, miasto, dzielnica.
W naszym przypadku mamy do czynienia z wartościami pomiarów. Są to na ogół wartości ciągłe. Tym razem zostawmy kolumny tak jak są. Jak mówi staroindyjskie przysłowie:
Jeśli działa, nie dotykaj.
Czy my w ogóle mamy wszystkie potrzebne cechy (features)? Czy to co mamy wystarcza, czy potrzebujemy szerszego kontekstu?
Na ten moment nie jesteśmy w stanie uzyskać większej liczby cech od naszego kolegi (ma ważniejsze zajęcia), więc ruszamy dalej z tym co mamy z nadzieją, że to wystarczy.
Podział na zbiory
Jesteśmy czyści. W zasadzie nasze dane są czyste. Wyczyszczone na tyle na ile mieliśmy siły i wiedzy. Czas na kolejny etap. Podzielmy sobie nasz zbiór danych na podzbiory:
- Treningowy
- Walidacyjny / Testowy
Pierwszy z nich posłuży nam do trenowania modelu, a drugi – do sprawdzenia jego skuteczności. Dlaczego trzeba tak robić? Przypomnij sobie anegdotę o uczniu z poprzedniego postu.
TL;DR: musimy model sprawdzać na danych, których nie używaliśmy do treningu.

Dlaczego nie rozdzielamy zbiorów walidacyjnego i testowego? Mamy bardzo mało danych – 178 próbek. W przypadku tak małych danych dzielenie zbioru na 3 podzbiory jeszcze bardziej ograniczyłoby nam liczbę danych do uczenia. Poza tym – tylko ćwiczymy 😉 Bardziej szczegółową odpowiedź możesz przeczytać tu i tu.
Dygresja: W przypadku małych danych można skorzystać z techniki sprawdzianu krzyżowego (cross validation). Na ten moment jednak pozostańmy przy klasycznym podziale.
Wróćmy na nasze podwórko. W fast.ai, do metody trenującej, podajemy listę indeksów wierszy, które mają być w zbiorze walidacyjnym. Przygotujmy taką listę! W naszym przypadku niech będzie to 25% całego zbioru danych.
# sprawdźmy, ile to jest 25%
valid_count = int(len(df) * 0.25)
# pomieszajmy wiersze w tabeli
df = df.sample(frac=1).reset_index(drop=True)
# i zapiszmy ID 25% "dolnych" rekordów
valid_idx = range(len(df) - valid_count, len(df))
3. Wybór modelu
Mamy dane! Nastał ten piękny moment, gdy możemy zabrać się za ten cały machine learning a nie jakieś NaNy, puste wiersze i brakujące kolumny. No to nauczmy model! Ale który?
Jak wspominałem w poprzednim poście, istnieje wiele różnych modeli wymyślonych przez mądrych ludzi.
W bibliotece fast.ai twórcy kładą nacisk na tworzenie modeli w jak najprostszy sposób. Obecnie na topie są sieci neuronowe, więc zrobili implementacje popularnych sieci gotowych do użycia i trenowania.
W tym przypadku, nie musimy się nawet mocno zastanawiać, jakiej sieci użyć. Tworzymy obiekt Learner i go trenujemy. Do danych “tabelarycznych”, tak jak w naszym przypadku, odpowiedni będzie TabularModel. Żeby było jeszcze prościej, użyjemy metody tabular_learner(), która automatycznie utworzy TabularModel za nas.
Do learnera przekażemy nasze dane, liczbę neuronów w poszczególnych warstwach sieci (na razie się nie zagłębiamy, jedziemy na “domyślnych” parametrach) i wybraną metrykę, którą podczas procesu uczenia będziemy śledzić.
W kodzie wygląda to następująco:
learn = tabular_learner(data, layers=[200,100], metrics=accuracy)That’s all folks! 🐰
4. Trening
Mamy dane. Podzielone. Oczyszczone.
Wybraliśmy metrykę.
Wytypowaliśmy model.
Czas na trening! W fast.ai ta operacja jest dosyć prosta i wymaga od nas uruchomienia jednej metody z obiektu Learner’a: fit_one_cycle().
Z hiperparametrów, które na tym etapie podajemy, mamy
- liczba “cykli” uczenia (tutaj uwaga dla już trochę bardziej zaawansowanych – to nie są epoki! – zerknij czym jest 1 Cycle Policy w oryginalnym artykule lub w tym poście)
- learning rate – czyli jak duże kroczki nasz algorytm ma stawiać w procesie uczenia
Podsumowując, ustawiamy liczbę cykli (ja zacznę od 1), ustawiamy learning rate na 1e-2 i trenujemy!
learn.fit_one_cycle(1, 1e-2)
I BANG! Mamy accuracy na poziomie 0.9772!
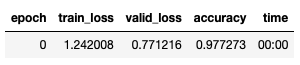
5. Ewaluacja
W zasadzie w poprzednim kroku dostaliśmy już wynik ewaluacji na zbiorze walidacyjnym. Ale cóż począć, gdybyśmy chcieli sprawdzić metrykę naszego modelu machine learning na innym zbiorze danych?
Twórcy fast.ai znowu ułatwiają nam życie jak tylko mogą. Chcesz zrobić walidację? Proszę, masz metodę validate(). Zrobione, pora na CS’a.
# jeżeli walidujemy na zbiorze, który wskazaliśmy w learnerze
learn.validate()
# lub opcjonalnie możemy podać zbiór, np.
learn.validate(learn.data.valid_dl)
6. Optymalizacja Hiperparametrów
Jeżeli nie pamiętasz, czym są hiperparametry w procesie treningu modelu machine learning, to zerknij do poprzedniego posta – tam znajdziesz skrótowe wyjaśnienie.
Jednym z hiperparametrów, który używamy w treningu, jest learning rate. Jak go ustawiać? Należałoby spojrzeć na krzywe uczenia i na podstawie doświadczenia z poprzednich eksperymentów ustawić.
No ale my nie mamy doświadczenia. Nie mamy też poprzednich eksperymentów…
Jak żyć?
Learning Rate Finder
Fajnie byłoby mieć narzędzie, które taki learning rate nam zaproponuje. Możemy skorzystać z techniki Learning rate finder – która metodą krótkich eksperymentów pozwala nam dobrać learning rate dla danego przypadku. W fast.ai mamy już gotową, “jednolinijkową” implementację.
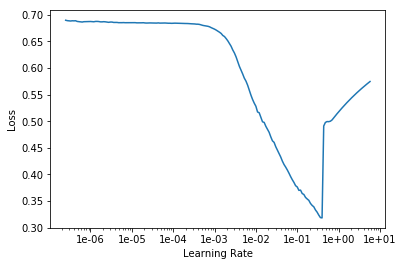
Inne hiperparametry również mogą być “wyszukiwane”. Mamy takie metody jak Grid Search czy Random Search. Są gotowe biblioteki, które wspomagają proces wyszukiwania hiperparametrów jak Optuna czy Hyperopt. Ale o tym opowiemy sobie kiedyś, bo to trzeba usiąść na spokojnie.
DOD – kiedy nasz model jest wystarczająco dobry
Na uczelni często słyszałem (pozdrawiam dr Komadę), że odpowiedzią na większość pytań jest: to zależy.
Kiedy nasz model machine learning jest wystarczająco dobry? To zależy…
Na początku naszej przygody wybraliśmy sobie metrykę. W naszym przypadku była to skuteczność (accuracy). Ale jaka wartość metryki będzie zadowalająca?
Wiadomo, im większa, tym lepiej. Ale małe są szanse, że osiągniemy 100%.
Chociaż kiedyś mi się to udało – trening poszedł rewelacyjnie, metryki pod sufit. Jarałem się jak lampion w roraty. Przez chwilę… Oczywiście okazało się, że popełniłem błąd i dupnąłem się gdzieś po drodze…
Wracając, w naszym przypadku możemy założyć, że gdy osiągniemy 90% skuteczności, to będzie klawo.
I teraz tak kręcimy parametrami i trenujemy, żeby osiągnąć nasz założony cel. Ahhh, machine learning…
Dotarliśmy?
W naszym przypadku jednak już przy pierwszym strzale dostaliśmy bardzo dobre rezultaty. Można świętować! Maciek na pewno ma jakąś butelkę na tak specjalną okazję.
7. Predykcje
Kiedy mamy już model uczenia maszynowego, który osiąga założoną przez nas skuteczność, czas go wykorzystać. Będziemy wykorzystywać nasz model, aby wydawać na świat predykcje. Fachowo nazywa się to inferencja, czyli odpytywanie wytrenowanego modelu o predykcje dla nowych danych.
Tu mała uwaga – bywa, że model do inferencji jest modyfikowany w stosunku do tego, który był używany w treningu. Stosuje się różne tricki w celu optymalizacji modelu, dostosowania predykcji do wymagań biznesowych, itp. Jeszcze kiedyś o tym pogadamy, a tymczasem…
Użycie danych do odpowiedzi na pytania
Pewnie zastanawiasz się jak odpytać wytrenowany model machine learning o predykcje dla pewnego zbioru danych?
Otóż w fast.ai jest to szalenie proste i wymaga od Ciebie skorzystania z metody get_preds() obiektu learner’a. Do takiej metody przekazujemy zestaw danych, dla których chcemy otrzymać predykcje. I już!
preds, _ = learn.get_preds(data.valid_ds)
pred_prob, pred_class = preds.max(1)
pred_prob, pred_classOprócz przewidzianych klas dostajemy “prawdopodobieństwo”, z jakim model twierdzi, że dana próbka należy do tej klasy. Nie jest to prawdopodobieństwo w klasycznym, statystycznym rozumieniu, ale chyba nie ma lepszego słowa w języku polskim, które by określało te wartości.
I tym sposobem pomogliśmy Maćkowi rozwinąć jego hobby w biznes. Od teraz nie będzie musiał próbować każdego wina, a jedynie co jakiś czas oznaczy kilka butelek ręcznie, żeby na podstawie tak przygotowanych danych zwalidować model po pewnym czasie. Bo przecież składniki, z jakich robi wino mogą się zmieniać. Przyrządy mogą szwankować. Możemy napotkać tzw. Concept Drift.
Pamiętaj więc, że warto monitorować metryki modelu w czasie. Do tego potrzeba opisanych przez człowieka danych, ale warto o to zadbać.
Co dalej?
Maciek jest szczęśliwy, ja swoje zrobiłem, a Ty wytrenuj swój pierwszy model machine learning! A przede wszystkim, eksperymentuj! Tutaj znajdziesz link do notebooka na Google Colab z pełnym rozwiązaniem.
Wystarczy, że klikniesz “Open in playground” i już możesz bawić się z przygotowanym kodem! Gdy jesteś na komórce z kodem do wykonania, możesz kliknąć na “Run” po lewej lub wcisnąć CTRL + Enter (⌘ + Enter na Mac).

Nie bój się eksperymentować z modelem uczenia maszynowego. Zmieniaj hiperparametry modelu: LR, liczba cykli treningu, liczba neuronów / warstw, przeglądaj dane, sprawdzaj różne ustawienia i ich wpływ na końcowy wynik. Nic nie wybuchnie 😉
A w kolejnych postach omówimy sobie każdy z kroków oddzielnie. Zajrzymy głębiej i lepiej rozpoznamy różne techniki i tricki. Nie obędzie się bez innych narzędzi i bibliotek, także stay tuned i do przeczytania!
Bibliografia / Linkografia
Jak zawsze, poniżej zbiór linków i książek, którymi posiłkowałem się podczas tworzenia tego artykułu. Jeżeli masz jakieś pytania, śmiało!
- Dokumentacja fast.ai
- UCI Machine Learning Repository – repozytorium, z którego pochodzi dataset
- Google Colab – tu piszemy kodzik i trenujemy
- Structuring Machine Learning Projects – kurs na coursera.org
Jeżeli uważasz, że jakiś link powinien się tutaj znaleźć, albo brakuje źródła w jakimś miejscu, daj proszę znać – uzupełnię! 😉
Zdjęcia
PS. Niestety, tak na prawdę to nie Maciek jest autorem badań na stronie Uniwersytetu Kalifornijskiego w Irvine. Upierał się, że tak jest, a ja mu uwierzyłem. Ale któż by odmówił koledze z koszykiem pełnym wina…

![[#w3linijkach] Jak pobrać dane z MySQL i zapisać do CSV w Pythonie?](https://uczymymaszyny.pl/wp-content/uploads/2021/05/andrzej-to-jebnie-340x227.jpg)

Absolutnie fantastyczne. Dziękuję.
Dzięki za dobre słowo, rad jestem, że się podoba! 🙂
Pobranie danych po SSL kończy się błędem.
SSLError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/requests/adapters.py in send(self, request, stream, timeout, verify, cert, proxies)
512 if isinstance(e.reason, _SSLError):
513 # This branch is for urllib3 v1.22 and later.
–> 514 raise SSLError(e, request=request)
515
516 raise ConnectionError(e, request=request)
SSLError: HTTPSConnectionPool(host=’archive.ics.uci.edu’, port=443): Max retries exceeded with url: /ml/machine-learning-databases/wine/wine.data (Caused by SSLError(SSLError(1, ‘[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:852)’),))
Można pobrać po zwykłym http
http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data
Bardzo dobra uwaga, dzięki! Poprawiłem już w kodzie, dodatkowo rozpisałem go, żeby było łatwiej zrozumieć, o co chodzi. Poprzednio wyszedł spory “jednolinijkowiec”, co w Pythonie jest fajne do pisania, ale gorzej się czyta 😉
Tutaj jeszcze wspomnę, że w przypadku problemów z SSL, o ile jest to uzasadnione, można skorzystać z
verify=Falsew metodzierequests.get()– dostaniemy wtedy warning, ale dane się pobiorą.response = requests.get(url, verify=False)Mega skomplikowany artykuł dla mnie, ale dopiero zaczynam naukę data science oraz machine learning. Czytając go uśmiałem się też nieźle bardzo pozytywnie.
Pozdrawiam :-).
Cieszę się, że mogę zapewnić dawkę rozrywki z kapką wiedzy 😀